Starting with Spark code
Parsing through the Spark code base can be challenging for some one new to Spark and wanting to dive deep in spark internals. But if we get introduced the main call flow of how spark process data and provide result we can get a overall idea of code structure and where to dive deeper based on our requirement. (The codes here are not accurate but have been simplified to capture the sequence of operations)
In a very basic Spark rdd program we :
- Create a spark context (
val sc = new SparkContext(conf)) - Create RDD (
val rdd = sc.textFile(fileName)) - Call some transformation operations like map and filter, shuffle etc. on the rdd (
val newRdd = rdd.filter(func)) - And call action operations to generate results (
val res = newRdd.collect()
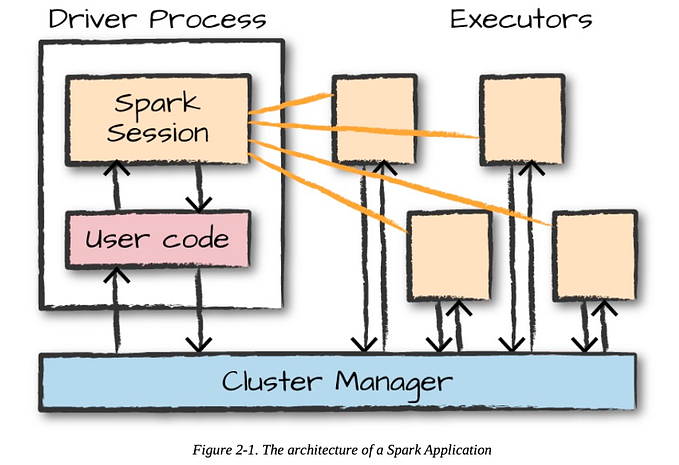
Following diagram shows the functional blocks inside Spark, how the above steps get processed and later we will show the main class and methods implementing it:

The user code runs in Driver JVM and is responsible for distributing the rdd operations to workers ( executor jvm) to get processed parallelly and then capture the result and present to user.
- SparkContext is the entry point for Spark functionality. User instantiates the SparkContext (SparkContext.scala) class and and then uses it to call API’s to create RDD.
- The RDD.scala is an abstract class implementing the common functionality and specific RDD’s extend this class and overrides some methods to handle those functionality in there own ways.
- The transformation functions called on these RDD results in another rdd but nothing is done to compute any of the transformation at this point. These transformation methods are simply adding an extra layer of computation over the iterator of the parent rdd. The compute() method in the new rdd adds that extra processing. So all these transformation methods returning a new rdd creates a pipeline of compute operation to build data from the previous rdd.
- At computations time, the rdds are computed per partitions separately. Some transformation result in each child partition depending upon only one parent partition but some transformations can result in a child partition depending upon multiple partition of parent. In such case shuffle rdds get created and those rdd’s have shuffle dependency on parent rdd.
- Once an action method of rdd object gets called, a job gets submitted to the DAGScheduler with that rdd. The DAG Scheduler creates a Result stage and then analyzes the dependency of the of the RDD on other rdds. And for every shuffle dependency in the rdd and all its parent rdds it creates a ShuffleMapStage. In each stage the output needs to get sent to the Shuffle writer. And the next stage starts by getting the data from the parent rdd shuffle id. Transformation inside a stage are pipelined and get executed for one specific partition. Once all the stages are created the stage gets submitted.
- On stage being submitted a task is created for each partition of the rdd. If the stage is a ShuffleMap stage it creates a ShuffleMapTask for each partition if it is a result stage a ResultTask is created for each partition. The shuffle map task takes the shuffle dependencies as argument to write data to that shuffle id after transformation. The result task takes a function to be run against the data in a partition. So we get a set of tasks called taskSets. These are submitted to the TaskScheduler.
- The task scheduler creates a task Manager for each set to keep track of task sets, its completion or individual task failures, committing the outputs etc. The scheduler then asks the executor backend for resources and assigns the tasks to those resources. These tasks are then serialized and set to the executors to be executed.
- The executor reserializes the rdd data sent to it and calls the run function on it. The results are serialized and sent back to the Driver and the task completion is informed to the backend to take proper action on task completion.
The following diagram shows the main Classes, methods and members implementing the functionality.

Here is brief intro to above classes and call flow
SparkContext
The user calls SparkContext() and instantiates the context object. This is the entry point for all the rdd program and represents the connection to Spark cluster. It uses the context to created rdd. The Spark context is responsible to instantiate other classes and required step to be able to break the job in to stages, tasks and schedule it on backend and provide the result back. For executing the code part the there important classes the Spark context instantiates are DAGScheduler, TaskScheduler and CoarseGrainedSchedulerBackend. There is only one SparkContext per JVM, and when actions are submitted to rdd, the spark context is used to access the Dag scheduler to submit Job to the cluster. Spark context has methods to be able to create rdd’s , methods to create broadcast variables and accumulators and also a method runJob to be able to post jobs to the cluster.
These are some of the members used to perform the execution of jobs and maintain the internal state of SparkContext:
_conf : SparkConf_env : SparkEnvdagScheduler: DAGSchedulertaskScheduler: TaskSchedulerscheduleBackend : CoarseGrainedSchedulerBackend_heartBeastReceiver : RpcEndpointRefapplicationId : String
When we instantiate sc=SparkContext it
- Creates Spark execution environment
- Create heartbeat receiver
- Creates Task scheduler
- Creates a DAG Scheduler
- Gets an Application Id
Then it has methods to be able to create RDD:
def parallelize(seq:Seq…)def range(start:Long, end:Long…)def textFile(path:String…)def binarFiles(path:String…)// Create an RDD from union of list of RDDdef union(rdds: Seq[RDD[T]…)// It has method for accumulators and broadcast variablesdef broadcast(value)def accumulator[T](initialValue:T)//Run a function on a given set of partitions in an RDD and pass the results to the given handler function. This is the main entry point for all actions in Spark.def runJob( rdd, func, partitions, resultHandler)
RDD
The rdd created is an object of specific type of RDD. All rdd class extends the abstract class RDD. The RDD class implements all the basic operations available on the RDD like map, filter etc. So the rdd returned to the user code has all these functions to use to perform operations on that data represented by RDD. Rdd represents an immutable partitioned collection of data that can be operated in parallel so to do that it has these properties internally :
A list of partition partitions. This is assigned at instantiation of the RDD class, and gets calculated by calling getPartitions() method. Different implementation if RDD can have there own methods to calculate the partitions. This function gets called only once and assigns the partitions to var partitions.
A list of Dependency dependencies_ : Sequence[Dependency[_]]. This is also calculated by calling the implementation of getDependencies(). This is called once and assign the dependencies. This take into account the RDD is checkpointed or not.
A function to compute each split. This will take the Partition as argument and return an Iterator to fetch the data
Each type of rdd has its own implementation of compute() to calculate the data in its own way and it returns an Iterator over the data. The iterator of the compute methods implements the fetching of data for this RDD. When we call a transformation method on rdd ( since rdd is immutable) it returns another rdd which has its own way to compute data. When we called filter So each new rdd creation basically is adding an additional layer of compute() method to calculated data from the previous rdd. This kind of creates a pipeline of operation through which data can be calculated to the final rdd starting from the original rdd.
When we call textFIle() it instantiate a HadoopRDD class. This returns an RDD which represents the data in the hadoop file. The HadoopRDD has its own specific way to split the data and have a list of partition. The compute() method for HadoopRDD implements its reading of data for the specific split and provide an iterator over it. Based on the Hadoop configuration, it first gets the input format specific reader which will read the hadoop file for that format for a given partition. The it implements the getNext() to be able provide the data one after another record.
When we call map and pass a function to Map, it returns another RDD of type MapPartitionRDD. If you look at the compute method , you will see it is simply applying the function f passed by user on top of the parent rdd iterator. Thus a pipeline is formed and the next rdd will have data read from hadoop file , then a filter applied to it.
The spark/core/src/main/scala/org/apache/spark/rdd/ has all the different types of implementation of RDD and can be explored to see how different ways splits are calculated for different types of rdd, how the compute is implemented for different rdd.
The RDD class has:
Reference to the SparkContext _sc
def compute(split: Partition, context: TaskContext): Iterator[T] , implemented by each subclass
Apart from these, the RDD has multiple methods which are either transform or action type for example filter(), map(), reduce() , count() etc.
A specific implementations of RDD, HadoopRDD :
HadoopRDD extends RDD class , it sets the _sc and dependencies to null. we would see:
It implements getPartitions as
getPartitions : Array[Partitions] = { //This relies on Hadoops InputFormat class to provide the splits and those splits are used to create Partitions and is returned val allInputSplits = getInputFormat(jobConf).getSplits(jobConf, minPartitions)… for (i <- 0 until inputSplits.size) {
array(i) = new HadoopPartition(id, i, inputSplits(i))
}}compute () {
// This uses Hadoop InputFormat.getRecordReader and implements
getNext as following: val inputFormat = getInputFormat(jobConf) reader = inputFormat.getRecordReader(split.inputSplit.value,
jobConf, Reporter.NULL) def getNext() { finished = !reader.next(key, value) }
}
Transform Function on rdd
This is the map function implementation in RDD class. The map function is simply instantiating MapPartitionsRDD with the current rdd this, and a function which takes the current iterator and for each intry calls the function passed by user in map function:
def map[U: ClassTag](f: T => U): RDD[U] = withScope {val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
So calling map on rdd we new rdd which applies a function on each entry from previous rdd.
Other transformation functions filter, flatMap return MapPartitionsRDD and is very similar to map.
Some other transformation you will find is coalesce, which returns another CoalesceRDD with reduced number of partitions.
ShuffleRDD: Some transformation as such that the child rdd depends on the same partiotn as that of parent partition. But for some , the child rdd depends upon multiple partitions of the parent. This kind of transformation returns a ShuffleRDD. For any SHufflRDD rdd, the dependencies is a list of ShuffleDependecies. In such cases the pipeline is broken into stages as the child can not be simply created by appying function on parent partition. It needs data from other partitions whihc are being handled in other tasks too. So for each such rdd in pipeline a new stage gets created. The parent stage being a shuffle Map stage which writes data to the Shuffle id and the child RDD which is a Shuffle rdd basically creates a reader for the shuffle ID and reads the data for that shuffle id instead of parent rdd iterator.
Action on rdd
While transformation functions creates a pipeline of transformation, it is the action which triggers the execution of these transformation and get the result. So actions like count, take reduce etc. on rdd triggers the execution.
Each such action call ends up calling the sc.runJob to submit a job to perform the action and get result. The runJob is called with the current rdd and a function.
For ex count() is implemented as :-
def count(): Long = sc.runJob(this, getIteratorSize _).sumThe runJob takes the current rdd and a function getIteratorSize.
The getIteratorSize takes an iterator as input and increments the counter for each entry.
def getIteratorSize(iterator: Iterator[_]): Long = {
var count = 0L
while (iterator.hasNext) {
count += 1L
iterator.next()
}
count
}The runJob returns an array of this count for each partitions. It calls sum on the array to give the total count for the rdd.
The collect() to get all elements of the rdd is implemented as following:
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}It takes the rdd and a function which takes an iterator and returns an Array of entries in the rdd. The runjob returns an array of entries from each partition. All these arrays are concatenated to get all the entries from the rdd.
This sc.runJob invokes the runJob method of the Dag scheduler.
DAGScheduler
The DAGScheduler is where all the stage creation and recursively adding the missing parents and creating tasksets etc. most important steps happen.
The sc.runJob is just a wrapper to DAGScheduler.runJob. The run Job is wrapper for submitjob. submitJob creates a JobWaiter for this jobid and submits a JobSubmitted event to the event process loop. It returns the waiter to runJob. The runJob waits for the submit job to finish.
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get) {
val waiter = submitJob(rdd, func, partitions, callSite,
resultHandler, properties)
ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)
}The JobWaiter is the class which waits for the job to finish. It also is responsible for calling the result handler on each task completion.
In the submitJob: The submitJob gets a new Job ID for this job. With the new Job id , it creates a JobSubmitted event. It passes the job id, the rdd, the function passed to runJob, partitions and properties.
The event is picked and handleJobSubmitted is called to handle the job submission.
This function names the passed rdd as finalRDD, calls createResultStage( ) with finalRDD, the function, the partitions array and jobId. The returned stage is called finalStage.
Then call getMissingParentStages(finalStage) on the finalStage. This getMissingParentStages method creates the ShuffleMpaStages by traversing all the parents of the rdd and wherver the dependency is of type ShuffleDependecy
def getMissingParentStages(stage: Stage): List[Stage] = {//We get all the dependency of the rdd and if it is ShuffleDependecy
// we create a ShuffleMapStage, if not we push it on to a stack.}
We call the above function till the stack is empty. So at the end of this function we have traversed all the dependency and its dependency so on and created a stage created for any shuffle dependency found.
Then the submitStage(finalStage) is called on finalStage.
The submitStage will submit this stage but before that it recursively submits any missing parent stages.
private def submitStage(stage: Stage) {
val missing = getMissingParentStages(stage).sortBy(_.id)
//If there is no missing parent then call submitMissingTask for this stage.
if (missing.isEmpty)
submitMissingTasks(stage, jobId.get)
else
for (parent <- missing) {
submitStage(parent)
}
}This function ends up calling recursively calling itself till it reaches a stage which does not have missing parent and submitMissing Tasks for that stage,
The submitMissingTask() takes just the stage and the jobId as argument.
It collects all the missing partitions to be computed.
Creates an outputCommitCordinator for the stage.
Creates a map for each partitions and its preferred location.
Then it creates a broadcast variable taskBinary. This taskBinary is a serialized version of rdd and a function. If it is the result stage it is the function passed to runJob. If it is a ShuffleMapStage, it is a serialized version of rdd and the stage.shuffleDep to which the data output is written to.
Then for each partition in the this stage it creates a Task to get a Taskset for this stage. if it is a shuffleMapStage , for each partition it creates a ShuffleMapTask() and if it is result stage then it creates a new resultTask(). So at the end we have a set of tasks which we pass on to the taskCheduler to process it further.
taskScheduler.submitTasks(new TaskSet(tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))TaskSchedulerImpl.scala
The task scheduler gets a set of tasks for the submitted stage. It creates a task set manager for each task set. That manager is responsible for management actions for this set of tasks like resubmit on failure etc.
After creating a manager, it calls the backend.reviveOffer() to get resource to schedule these tasks. Depending upon the master and the mode, the backends will be different and will implement the revive offer accordingly. We will look into the yarn master case. In this case the backend is CoarseGrainedSchedulerBackend. The backend returns a set of workerOffer to task scheduler by calling its resourceOfferes() method. To which the task scheduler assigns the tasks to and let the backend submit it to the executors to run it.
CoarseGrainedSchedulerBackend
A scheduler backend waits for coarse-grained executors to connect. Executors may be launched in a variety of ways. The coarseGrainedSchedulerBackend register executors who connect to it. When taskScheduler calls the reviveOffer() it calls makeoffers . The makeoffer() retrieves the collection of all active executors. For each active executors, it creates a new WorkerOffer which is nothing but a class representing free resource available on an executor. It gets a collection of WorkerOffer with all active executors. This it passes it back to the task scheduler by calling method scheduler.resourceOffers(workOffers) as an offer of resource so that scheduler can attach tasks to those offers.
The Task Scheduler ( TaskSchedulerImpl.scala) fills each node with tasks in a round-robin manner so that tasks are balanced across the cluster. The task scheduler’s resourceOffers() takes the collection of workOffers, filters out any black listed executors, calculates the number of available slot by adding the number of cores for all executors. Then it fills the offer with taskDescs and returns a list of taskDescs back to the backend. The backend calls launchTasks() on this list of tasks returned by task scheduler.
private def makeOffers() {val taskDescs = withLock {val workOffers = activeExecutors.map {
case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores,
Some(executorData.executorAddress.hostPort))
}.toIndexedSeq
scheduler.resourceOffers(workOffers) // Offering scheduler a list
//of WorkerOffer and gets a list of taskDescs in response.
}
if (!taskDescs.isEmpty) {
launchTasks(taskDescs) // Call launchTasks on the list.
}
}
The launchTask flattens the sequence and then for each entry of TaskDescription , it serializes it. It pulls the executorID assigned to this task by the task scheduler, pulls the executorData for that id , creates a LaunchTask message with the serialized task and sends it to executorEndpoint. This message gets sent to the executor and executor receives the erialized task it has to execute.
The communications happens using the messages defined in CoarseGrainedClusterMessage.scala.
The CoarseGrainedClusterMessage.scala defines the messages from driver to executor and executor to driver.
For ex:-
// Driver to executors messages are these case class
case class LaunchTask(data: SerializableBuffer) extends CoarseGrainedClusterMessagecase class KillTask(taskId: Long, executor: String, interruptThread: Boolean, reason: String) extends CoarseGrainedClusterMessage// Executors to driver
case class RegisterExecutor(executorId: String,executorRef: RpcEndpointRef,hostname: String,cores: Int,logUrls: Map[String, String])extends CoarseGrainedClusterMessagecase class StatusUpdate(executorId: String, taskId: Long, state: TaskState,data: SerializableBuffer) extends CoarseGrainedClusterMessage
Executors:
On executor side we have CoarseGrainedExecutorBackend.scala
On the executor JVM on receiving the LaunchTask message, we decode the data to get the taskDesc back and call executor.launchTask :
case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, “Received LaunchTask command but executor was null”)
} else {
val taskDesc = TaskDescription.decode(data.value)
logInfo(“Got assigned task “ + taskDesc.taskId)
executor.launchTask(this, taskDesc)The launchTask in Executor class is a spark executor backed by a threadpool to run tasks.
Executor.scala:
Spark executor deserializes the task and calls the run method of the task to execute the task. For that a TaskRunner instance is created using the serialized taskDescrition instance we got from the driver. The taskRunner is passed to threadPool.execute() which calls ThreadRunner run().
Here in run, the task is deserialized and the run method is called on it. The results are serialized and sent back to the driver as status update messages. The taskSetManager and task scheduler handles these task completion and sends the result back to the user function finally.
Will take a little into what is there in the task class.
Task
We saw that executor calls the run method on the task. The task is the actual unit of execution. The tasks are of two types ShuffleMapTask and ResultTask. The very last stage (finalStage) in a job consists of multiple ResultTasks, while earlier stages consist of ShuffleMapTasks. A ResultTask executes the task and sends the task output back to the driver application. A ShuffleMapTask executes the task and divides the task output to multiple buckets (based on the task’s practitioner).
The ShuffleMapTask deserializes the data and gets the rdd and the shuffleDepdency. With the shuffle dependency handle and partition id a writer is created and using the rdd iterator the calculated output is written to the shuffle. This shuffle data is read by next stage by setting up iterator over this shuffle id.
The ResultTask deserializes the data and gets the rdd and the function. IT calls the function over the rdd.iterator.
def runTask(context: TaskContext): U = {val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)]func(context, rdd.iterator(partition, context))
}
We can not do justice in capturing the code of spark in a simple article but hope this gives some basic starting point to explore the code. After getting an idea of core operation we can expand into Spark SQL, Spark Streaming and see the call flow and the classes handling those operations and also look into how spark submit deploys the Spark application to cluster.